Managing Machine Learning Lifecycles with MLflow

This is PART 3 of our 3 PART SERIES on the machine learning lifecycle management framework MLflow.
See PART 1 here and PART 2 here.
In PART 3, we are going to use the concepts from PART 1 and PART 2 to build a Python API and integrate it into a React web application. This application will allow us to:
· Quickly try hyperparameter combinations to train linear and logistic regression.
· Deploy best estimators and do inference.
Before diving into the code, let’s first try to get a brief understanding of what our little app will be able to do!
Overview of the Application
Our React application will allow you to use some of the tracking and model deployment features of MLflow with very little code. More specifically, you will be able to:
· Use grid search to quickly try different hyperparameter combinations for linear and logistic regression. To help you achieve this, the app uses scikit-learn’s GridSearchCV, LogisticRegression, and LinearRegression.
· Deploy the best estimators trained with GridSearchCV locally (more about MLflow deployment in PART 2).
· Do inference with the best estimators and save predictions.
The app isn’t really meant to deploy MLflow models in production, but it could help you get a better idea of what MLflow can do and how to use it for deployment.
Prerequisites for the App
As with our previous apps, there are two main things to take care of in terms of dependencies:
· Python packages.
· The web application environment.
As far as Python is concerned, you will need:
· MLflow.
· Scikit-learn.
· Pandas.
· NumPy.
· Flask, Flask-RESTful, and Flask-CORS.
If you’ve read PART 1 and PART 2 in our MLflow series, you should already have everything installed, except for maybe the Flask packages. Assuming that you are using Anaconda, run the following commands in the Anaconda terminal to install Flask dependencies:
conda install -c conda-forge flask
conda install -c conda-forge flask-cors
conda install -c conda-forge flask-restful
For web development, install Node.js on your machine, following the instructions on the Node.js website.
If you are on Windows, you can also install Git. Git will allow you to work with GitHub repositories.
If you are on macOS or Linux, use either Git or any other terminal of your choice. But keep in mind that terminal commands for you may be different from what we have in the guide.
Building the API
Now, let’s have a look at the code behind our app, starting with our Flask-RESTful API.
Our API will handle the following:
· Tracking experiments with MLflow.
· Training of LogisticRegression or LinearRegression with GridSearchCV.
· The deployment of the best estimators trained with GridSearchCV.
· Inference with deployed estimators.
Below, we’ll take a look at our API. We’ll be providing step-by-step explanations to ensure that you perfectly understand what is going on.
Importing Dependencies
First up, let’s import the dependencies for our API:
Here’s how we will be using these dependencies:
· Flask, Flask-RESTful, and Flask-CORS will help us build our API.
· MLflow will help us track experiments and models.
· sklearn.datasets will provide us with toy datasets for testing.
· sklearn.model_selection.GridSearchCV will be used to train sklearn.linear_model.LogisticRegression and sklearn.linear_model.LinearRegression.
· Pandas, NumPy, and JSON will be used to process data passed to the API.
Setting a Tracking URI
For our API, we’re going to set a custom tracking URI:
With this code, MLflow would log performance metrics, parameters, and models to ./app/MLflow_web_app/mlruns on the web server. You can type in any other path that makes sense to you. Note that in the final code for the React app, the tracking URL is slightly different because the app is dockerized.
Setting up the API
Next, we need to create our Flask app. If you’ve read our previous posts, this code snippet will be familiar to you:
Here, we do the following:
1. Create a WSGI (web server gateway interface) application (line 2).
2. Set up Cross-Origin Resource Sharing (CORS) for the application (line 3).
3. Create an API entry point to our application (line 4).
Setting up Arguments
As our next step, we need to set up the arguments that will be passed to our API endpoints. We will be using flask_restful.reqparse.RequestParser objects to handle input arguments. We will create several RequestParser objects to handle different types of arguments.
Here are the RequestParser objects that we will use:
· data_parser — handles the training dataset, the estimator type, and the MLflow experiment name.
· gridsearch_parser — handles the parameters of GridSearchCV, such as n_jobs or cv.
· classification_parser — handles the hyperparameters of LogisticRegression. If you choose to train logistic regression, these are the hyperparameters that will be passed to the param_grid parameter of GridSearchCV.
· regression_parser — handles the hyperparameters of LinearRegression. If you choose to train linear regression, these are the hyperparameters that will be passed to the param_grid parameter of GridSearchCV.
· deployment_parser — handles the deployment of the best estimators that GridSearchCV trained. This parser will allow you to select the experiment and the run ID under which the desired estimator was logged.
· inference_parser — handles inference after you deploy a model.
Let’s go over our RequestParser objects one by one so that you understand what we are doing. But before we proceed, a few things to keep in mind:
· All numeric values are expected to be provided as strings. If you are providing several values for some hyperparameter, they need to be in one long string, and the numbers need to be separated with commas. For example, if you wanted to pass the values [1.0, 1.5] to the parameter C of LogisticRegression in Python, you would need to pass the values as “1.0, 1.5”.
· Before passing any numeric arguments, you need to convert (or serialize) them to JSON. In Python, you can use json.dumps to do this. Our “1.0, 1.5” would become ‘“1.0, 1.5”’ after being serialized. ‘“1.0, 1.5”’ is what you would actually pass to the API for the hyperparameter C.
· Our RequestParser objects will be converting any numeric arguments (integers or floats) to Python strings. We do this because some numeric arguments accept the Python None. Strings make handling both None and numbers easier. Our script will check if the passed value is “None”. If true, the value will be converted to the Python None— otherwise, the value will be converted to floats or integers.
· After being converted to strings, numeric arguments (integers or floats) are inserted into Python lists. We do this because the parameter param_grid of GridSearchCV expects estimator hyperparameters as a dictionary of lists. Our API would thus turn ‘“1.0, 1.5”’ into [‘“1.0, 1.5”’]. We would then put this list under the appropriate key and pass it to GridSearchCV.
· To be able to pass something like [‘“1.0, 1.5”’] to a scikit-learn estimator, we would need to convert the string into numbers. To do this, the string inside [‘“1.0, 1.5”’] would need to be deserialized using a function like json.loads. This would give us “1.0, 1.5”. Then, we would split the string, using the comma as a separator, and then iterate over the numbers, converting them to floats, integers, or None, depending on the values.
Data_parser
Let’s now take a look at our argument parsers.
First up, we have data_parser:
data_parser handles the following arguments:
· data — the data that will be used for training.
· model — the name of the model that will be used for training.
· experiment_name – the name of the MLflow experiment that the runs will be logged to.
Gridsearch_parser
gridsearch_parser handles the arguments that we can pass to scikit-learn’s GridSearchCV.
We’ve implemented only three of the arguments of GridSearchCV:
· n_jobs — the number of processors to run training on.
· cv — the number of cross-validation folds to run.
· return_train_score — whether to include training scores in the final results.
Note that the value we pass to n_jobs will also apply to the n_jobs parameter of our estimator. Additionally, even though the values for these parameters don’t need to be inside a Python list, we will place them in lists anyway (by doing action=”append”). This is so that we can handle all numeric arguments passed to the API with just one function.
Classification_parser
classification_parser handles the arguments passed to LogisticRegression:
We’ve implemented the vast majority of the hyperparameters of LogisticRegression in the API. You can check out the full list of hyperparameters here.
Regression_parser
regression_parser handles the arguments passed to LinearRegression:
We’ve implemented all hyperparameters of LinearRegression except for n_jobs. We are using the value passed to the n_jobs parameter of GridSearchCV anyway, so there’s no need to define a separate argument here.
Deployment_parser
deployment_parser handles the deployment of saved models:
We have the following arguments here:
· run_id — the ID of the run that the desired model was logged to.
· experiment_name_inference – the name of the experiment that the run ID is located under.
Inference_parser
Finally, inference_parser handles arguments for inference:
The arguments here are as follows:
· data_inference — the data that will be used for inference.
· prediction_file_name — the name of the file that predictions will be saved to.
Building our API endpoints
As our next step, we are going to build endpoints for our API. We are going to have two endpoints:
· /track-experiment – will be used to train GridSearchCV and track experiments.
· /deploy-model — will be used to deploy models and do inference.
Let’s go over these endpoints more in-depth.
Endpoint for Tracking Experiments
With Flask-RESTful, you create endpoints by inheriting the class flask_restful.Resource. In your inherited class, you then implement methods for the HTTP requests that you want to send. Additionally, you can include helper methods to help you handle your requests.
Our class for tracking experiments is TrackExperiment. Its complete code is as follows:
If you’ve seen our React apps for Hugging Face and TPOT, you’ll notice that this endpoint is way more complex than anything we’ve had previously. However, it’s actually pretty simple.
Let’s go over the methods implemented in the class TrackExperiment so that you get a better idea of what we are doing.
Post
First up, we have the method post. This method handles POST requests to our API endpoint /track-experiment.
In this method, we:
1. Get the arguments that are handled by data_parser and gridsearch_parser (lines 10 and 13).
2. Set the names of numeric arguments for grid search that should be converted to integers (line 17). We will use the custom method self.process_numeric_args to process numeric arguments. As we mentioned earlier, our API converts numeric arguments into strings to be able to handle cases when the provided value is None. For grid search, we don’t have float arguments — only integers.
3. Process numeric arguments in gridsearch_args, converting them to None or integers, depending on the provided value (lines 20–21).
4. Check which type of model was requested from the API — logistic regression or linear regression and proceed accordingly (lines 25 to 51).
· If logistic regression was selected, parse its arguments (line 28), define numeric float and integer arguments (lines 31 and 34 respectively), process the numeric arguments (lines 37 to 39), and instantiate a LogisticRegression object (line 42).
· If linear regression was selected, parse its arguments (line 48) and instantiate a LinearRegression object (line 51). We haven’t defined any numeric arguments for LogisticRegression, so there’s no need to process anything here.
5. Extract the integer value for the parameter cv of GridSearchCV (line 55) from its list. As a reminder, even though parameters for GridSearchCV are single values rather than lists, we’ve wrapped them in Python lists so that we can handle every numeric value passed to our API with a single function.
6. Copy the argument n_jobs from gridsearch_args to config_args (line 58). We do this because we want our estimator and GridSearchCV to have the same value for n_jobs. Note that n_jobs here is a single integer inside a Python list — we keep the list for config_args because estimator parameters passed to GridSearchCV need to be in lists.
7. Extract the integer value for the parameter n_jobs of GridSearchCV (line 61) from its list. Again, we do this because GridSearchCV expects an integer or None, not a Python list with integers.
8. Run GridSearchCV with the provided arguments (lines 65 to 69), using our custom method self.train_gridsearch.
9. Return an OK message (lines 72 to 74) that contains a success message, a run ID, and the name of the current experiment. We will need the run ID and the experiment name to do inference later.
Process_numeric_args
Let’s move on to process_numeric_args. This method converts numeric arguments into floats, integers, or None, depending on what is provided. To help you understand the method, we’ve added a docstring to it.
In process_numeric_args, we:
1. Iterate over the keys of the numeric arguments that should be converted to floats (lines 34 to 49).
a. Deserialize the JSON string under the current key (line 36). We call json.loads(args[arg][0]) to do this. We access the zeroth element of the current argument because the serialized string is stored in a Python list, as we established earlier.
b. Split the string using commas as separators (line 39). This gives us a list of numbers in the form of Python strings.
c. Iterate over the string numbers (lines 42 to 49), checking if they contain “None” in them. If the current value contains “None”, it is converted to the Python None. Otherwise, it is converted to a float.
2. Iterate over the keys of the numeric arguments that should be converted to integers (lines 52 to 67). The process is exactly as with floats, but we convert string numbers to integers (line 67) rather than floats.
3. Return the processed arguments (line 70).
Train_gridsearch
The final method in TrackExperiment is train_gridsearch. This method takes all the arguments provided to the endpoint and runs GridSearchCV with them. train_gridsearch is actually the simplest method of the three, and you’ll also be familiar with it if you’ve read the previous two parts in our MLflow series.
In this method, we:
1. Set an experiment with the experiment name provided to the API (line 41).
2. Enable automatic logging for scikit-learn models (line 44).
3. Instantiate a GridSearchCV object with our estimator, parameter grid, and grid search arguments (line 47).
4. Parse our JSON training dataset as a pandas DataFrame (line 52).
5. Extract the features and labels from our DataFrame (lines 55 and 56).
6. Start an MLflow run (line 59).
7. Obtain the ID of the parent run (line 61). This run will contain the best estimator trained by GridSearchCV. In contrast, child runs under the parent run will contain the individual estimators evaluated by the algorithm.
8. Train GridSearchCV (line 64).
9. Disable autologging (line 68) after training is complete.
10. Return the ID of the parent run (line 71).
This concludes the endpoint for training and MLflow tracking.
Endpoint for Deploying Models and Inference
Let’s move to our endpoint for model deployment and inference. The class for this endpoint is DeployModel and looks like this:
It’s way simpler than TrackExperiment, but it has some other things to keep in mind.
DeployModel implements methods for two HTTP requests — GET and POST. The method for GET (get) handles model deployment, while the method for POST (post) handles inference.
Let’s go over these methods one by one to understand what they do.
Get
The get method is as follows:
In get, we:
1. Get the arguments that are handled by deployment_parser (line 9).
2. Set the experiment under which the desired model is located (line 12).
3. Get the experiment ID of the current experiment (line 13). We need the ID to navigate to the directory where the model is saved.
4. Load the model logged under the selected experiment and ID and store it in our Flask app’s config (line 16). We store the app to be able to access it from the post method.
5. Return an OK message that will be displayed in the React app (line 19).
Post
The method post allows us to do inference and save predictions to a CSV file. It will also help our React app generate download links for the CSV files.
In post, we:
1. Get the arguments that are handled by inference_parser (line 7).
2. Parse our JSON inference dataset to a pandas DataFrame (line 10).
3. Load our model from the Flask app’s config, do inference with it, and save the predictions to a file with the provided filename (line 13).
4. Return an OK message and the name of the file that the predictions were saved to (line 16). The name will be displayed in the React app and will allow you to download the file from the application’s server.
Launching the Flask API
Finally, we add our endpoints to the Flask-RESTful API:
And then launch the app:
That’s it for the API! We can now incorporate it into a React web application.
Using our API in a React Application
Now that we’ve had a look at the Python API, let’s move on to the app itself. Note that the API code in the React app differs slightly from what we’ve done above — most notably, the URLs were changed so that the API could run in a Docker container.
Cloning the repository
First up, run this command in the terminal to clone the application’s repository.
git clone https://github.com/tavetisyan95/mlflow_web_app.git
This repository contains the application along with a few toy datasets to help you test the app.
Getting Docker
Because our app is dockerized, you will need to have Docker on your machine. Go here and download the appropriate version of Docker for your machine.
Starting the App
After you install Docker, make sure to launch it on your machine. Then, open the terminal, navigate to the root path of the cloned directory, and run the following command:
docker-compose -f docker-compose.yaml up -d --build
This will launch the dockerized application. You might need to wait a minute or two for Docker to install dependencies. After the containers start, the Docker app will show something like this:
Once the containers are running, navigate to http://127.0.0.1:3000 to access the app.
Configuring Endpoints
By default, the endpoint configuration in our React app looks like this:
If you will be running the app locally, you should not need to change anything here. Otherwise, plug in the URL of the server where the app will be hosted, as well as edit the ports and endpoints if necessary.
The app is configured to run on the following ports:
· 3000 — the port of the web server.
· 5000 — the port of the Flask-RESTful API.
· 8080 — the port of http-server.
Make sure that these ports are unoccupied and accessible in your environment.
Note that changing ports in config.js doesn’t actually change the ports that the app is run on — it only changes which ports the app tries to send HTTP requests to. You would need to make some changes in the code if you wanted to change the ports, but you shouldn’t have to.
Training GridSearchCV and Logging with MLflow
Upon launch, you will see the training screen of the app:
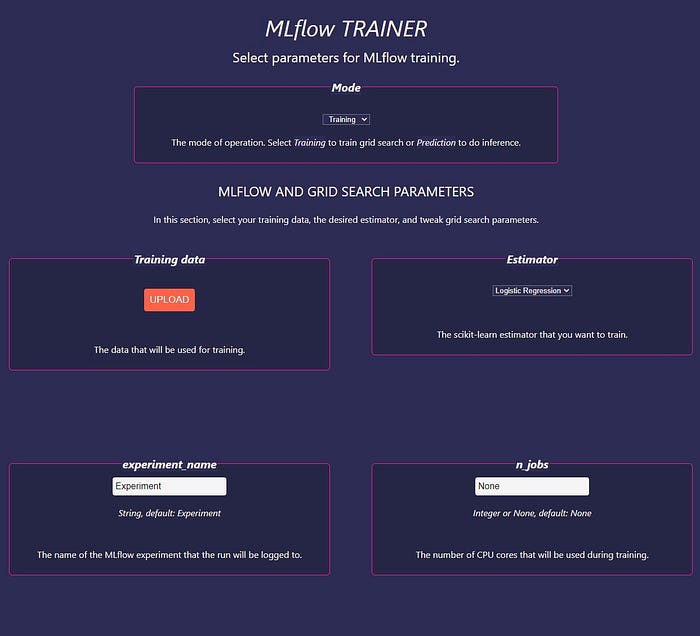
Here, you can select the operation mode — training or prediction — and select hyperparameters for training with GridSearchCV.
The operation mode is set to training by default — there’s no need to change this right now.

Selecting an Estimator
To start training, you need to first select the estimator. We’ve incorporated two scikit-learn estimators into our app — LogisticRegression and LinearRegression. Click on the selector and choose the appropriate estimator.
Selecting a Dataset
Next, select a dataset. Click the UPLOAD button and choose one of the training datasets included in the project. You can find the datasets in the root directory of the app.

Use dataset_classification_training.csv for logistic regression and dataset_regression_training.csv for linear regression. You can use any other dataset that is suitable for your task, but remember that it should not have an index column and that the labels should be under a column named “Target.”
The application expects datasets in a format like this:
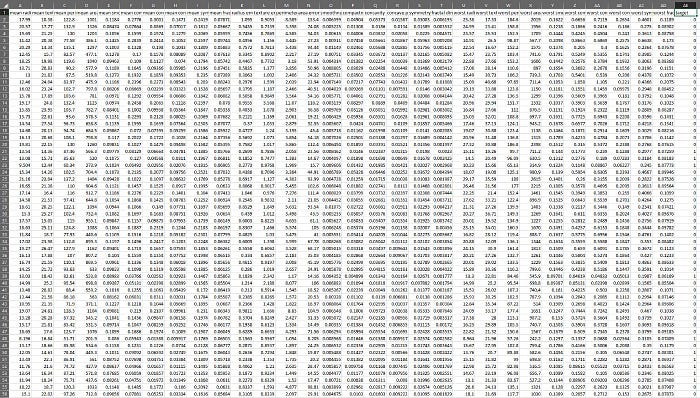
With pandas, you would get the correct dataset structure by using this command:
dataset_df.to_csv(“dataset.csv”, index=False)
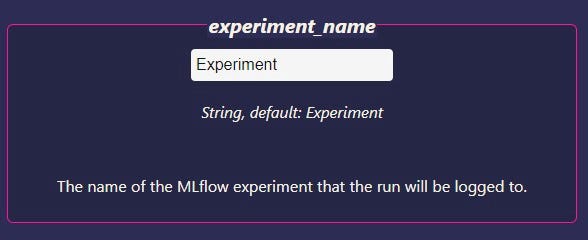
Selecting an Experiment Name
Next, you can enter an experiment name. By default, all runs are logged under an experiment called Experiment. You can change this at any time before running the trainer to keep your runs organized.
Then, take a look at the parameters for GridSearchCV. We’ve included only three of its parameters to simplify the app’s implementation — n_jobs, cv, and return_train_score. The value you enter for n_jobs will also apply to the n_jobs parameter of the estimator you selected.
You do not need to change the default parameters for GridSearchCV for the app to work.
Selecting Estimator Hyperparameters
Scroll down to the ESTIMATOR HYPERPARAMETERS section and choose hyperparameter values for the selected estimator.
There are four main types of hyperparameters in our app. First up, we have hyperparameters with several options, like penalty:
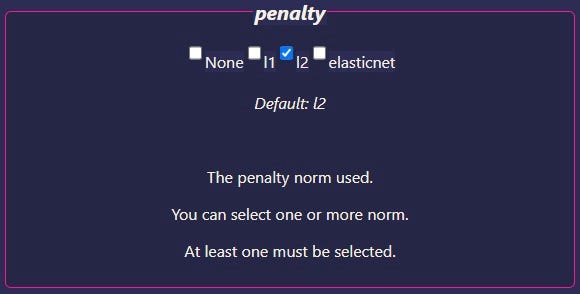
You can select one or more options for training. The app expects you to select at least one — if you uncheck all the options, the API may throw errors at you.
Whenever possible, GridSearchCV will try all of the selected options while training. We say “whenever possible” because some hyperparameter values don’t work with others. For example, the penalty norm L1 doesn’t work with LogisticRegression solvers newton-cg, lbfgs, and sag. With that said, GridSearchCV should work even if you select incompatible hyperparameters — GridSearchCV should just skip them and move on to the next ones.
The second hyperparameter type is Boolean hyperparameters. They look like this:

You can select either of the values or both. GridSearchCV will try all of the selected values for the hyperparameter.
The app again expects you to select at least one value.
The third hyperparameter type is number list hyperparameters.

You can enter one or more numeric values for these hyperparameters. Each value must be separated with a comma, like so:

The fourth and final type of hyperparameter is single-number hyperparameters. Here’s an example:
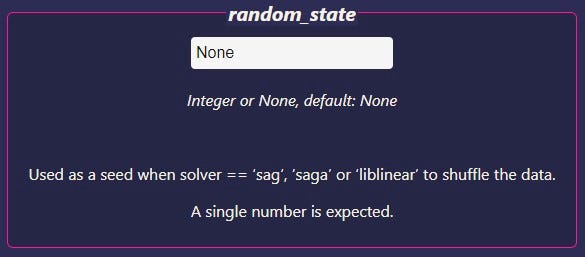
For these hyperparameters, you are expected to pass either None (when supported) or a single number. The app may work if you pass several values, but for parameters like random_state, passing more than one value doesn’t really make sense.
Starting Training
After you are done tweaking hyperparameters, scroll back up and click Train Grid Search. When you click the button, the app will:
1. Grab all the values you’ve entered on the webpage.
2. Serialize all numeric values to JSON strings.
3. Send all the parameters in the body of a POST request to our API, launching training.
The Train Grid Search button will also disappear and stay hidden while training is in progress. You will see the status message Training… under RESPONSE as well.
Once training is complete, the Train Grid Search button will reappear, and you will see the status message Training Complete! The API will additionally return two values:
· The ID of the parent run where the best trained estimator is saved.
· The name of the experiment that the run was logged to.
Using these two values, you will be able to access the best trained estimator later.
This concludes training with our app.
Doing Inference with Trained Estimators
To do inference, scroll to the top of the app and choose Prediction under Mode. The training UI will disappear, and you will see the prediction UI:
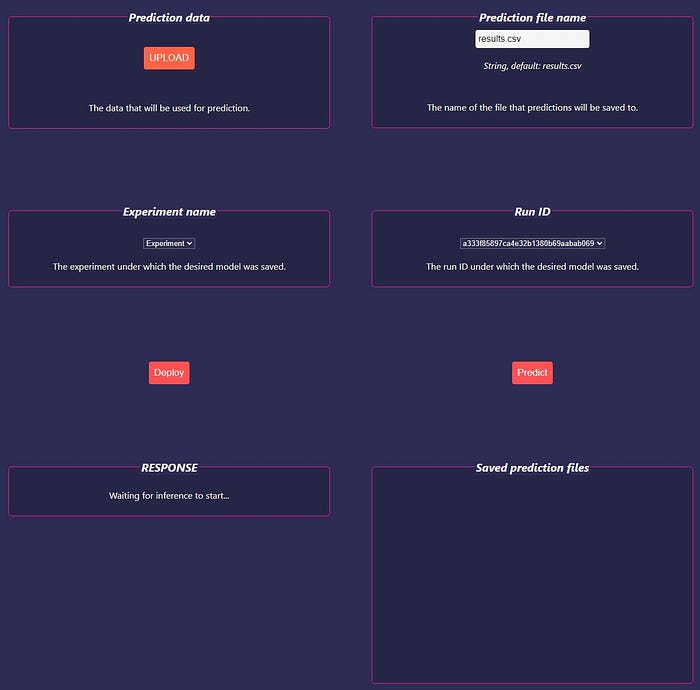
To start inference, do the following:
1. Click the UPLOAD button and upload a dataset to do predictions with. You can find two test CSV datasets in the root directory of the project — dataset_classification_prediction.csv and dataset_regression_prediction.csv.
2. Enter the name of the file that predictions should be saved to. The app is intended to save predictions to CSV files, but other formats might work as well.
3. Select the experiment under which the desired model has been saved. Once you select an experiment, you will see the run IDs that were logged under it.
4. Select the run ID of the desired model.
Then, click Deploy — this will load the best estimator logged under the selected experiment and run ID. Note that when re-using the same model for predictions, there’s no need to re-deploy it every time before inference. But if you want to use another model, you will need to select its ID and deploy it.
Next, click Predict. After inference is complete, you will see the name of the CSV file under Saved prediction files. Existing files are overwritten on the server and don’t get added to the list, while new files do appear on the list.

Click on a filename to download the respective file.
And this concludes inference with our application!
Limitations of the Application
Although quite a bit functional, our React application has a number of limitations:
· The app doesn’t offer an easy way to access training logs with the MLflow UI, which is a pretty major limitation. This is because the app is running from a container.
· No error messages or warnings are shown when something goes wrong. The only instance when the app handles exceptions is when you try to do training or inference without selecting a dataset. The app shows in its response area that a dataset is not selected.
· Many parameters from GridSearchCV, LogisticRegression, and LinearRegression are missing from the app or are only partially implemented for the sake of simplicity. For example, the parameter cv of GridSearchCV accepts not only integers but also None and iterables. We’ve implemented support only for integers and None.
· The app doesn’t set any seed values for global random generators, which will make experiments less repeatable. You can fix this by either adding a global seed parameter in the UI or by manually setting a seed in the API code yourself.
Next Steps
This guide had a lot to take in, but you now hopefully understand what you can do with MLflow and how you can incorporate it into a fully-fledged user interface!
As further steps, you could try to implement other scikit-learn algorithms. You could also try to address some of the limitations of the app, like the lack of error messages or warnings.
Play around with the app and see what you can do! Until next time!
