
Written by Tigran Avetisyan
This is Part 3 of our 3 PART SERIES on Hugging Face.
See Part 1 here and Part 2 here.
In the previous two blog posts in our Hugging Face series we explored 2 topics:
- Inference with pre-trained Hugging Face models.
- Fine-tuning pre-trained Hugging Face models on a custom dataset.
In this post, we are going to build on top of what we’ve done in Part 2 and craft a simple Flask RESTful API, to be able to serve predictions to end users. In addition, we will show a simple front-end to demonstrate how to integrate your fine-tuned model and the API into a web application.
Let’s get started!
Building A Simple API With Flask
First up, let’s build a minimal REST API to be able to make our Hugging Face model accessible via HTTP requests.
We’re going to cover the basics of API building in this guide — for more information, you should have a look at the quickstart guides of Flask and Flask-RESTful.
Importing Dependencies
Let’s start by importing dependencies necessary for our task:
If you’ve been following our previous posts in the Hugging Face series, you should already have the Transformers library installed. So the only thing you would need to do to get started is to install Flask:
Flask-RESTful:
And Flask_CORS:
After that, we instantiate a Transformers tokenizer and model for our prediction tasks — just like in the previous guides:
We’re using the model “distilBERT-tweet-emotion” that we trained in the previous post in this series. You may use any other model of your choosing — the process will be more or less the same.
Building a processing function for predictions
Our next step would be to set up a processing function for the model’s predictions. Recall that the model provides predictions in the form of logits if we want to make predictions readable to us, humans, we need to convert them to their corresponding class names.
To do this, we’re going to use this function:
This is the same function that we used at the end of our previous guide to interpret logits. As a reminder, this function:
- Transforms logits to probabilities via the
softmaxfunction. - Extracts the index of the class with the highest probability.
- Converts the predictions to class names with the help of our
class_namesdictionary.
Building the API
Creating a Flask application
Now, we can proceed to building our API with Flask and Flask-RESTful!
Here’s how we set the foundations for our API:
The class Flask defines a WSGI (Web Server Gateway Interface) application that will handle our requests, while the Api class provides an entry point for that application. CORS sets up Cross Origin Resource sharing for app, which isn’t necessary for a basic API but is necessary for the React app we’ll show later.
Notice that we pass the value __name__ to the import_name parameter of the class Flask. __name__ is a variable that contains the name of the current module. If you’re running your Python script directly (i.e. you aren’t importing it from another script), the value of __name__ will be __main__. Otherwise, the variable will contain the name of the script that you are importing.
__name__, thus, allows us to define where our app should be run. This helps the app find resources on the filesystem and can simplify debugging.
Our next step would be defining the arguments that should be provided with each request. This is done via the RequestParser class:
Using the add_argument method of our parser object, we define an argument named “Sequences”, which is of type str. We indicate through required=True that this argument is required for a call, meaning that requests without an argument under the key “Sequences” will return an error.
Via the help parameter, we provide a description that is returned when the provided argument is invalid. As for action=”append”, it allows the parser to handle cases when we pass multiple values in “Sequences.” Without this action defined, the parser would only accept one value.
Building an Endpoint for Inference
Our next step is defining an endpoint for our API. In Flask-RESTful, this is done by creating a class for each of the endpoints. The endpoint classes need to inherit from Flask-RESTful’s Resource class, which allows us to implement HTTP requests (and more) in our endpoint class.
Endpoints are very easy to create in Flask-RESTful:
We are going to name our endpoint class Inference — you may use any other name that you find indicative of the purpose of your endpoint. In the class, we define a method get, which will be called whenever we send a GET request to our application via this endpoint.
You should familiarize yourself with HTTP requests to be able to figure out which method to use.
In the get method, we:
- Parse the arguments we defined earlier.
- Tokenize and pad the input sequence.
- Feed the tokenized sequence into our model to obtain a prediction.
- Process the prediction to convert it into a class name.
- Return the prediction along with a status code (in our case, 200 to indicate that everything went OK).
After this, we need to add the endpoint to our API, like so:
Here, we pass:
- Our endpoint class Inference to let the API know how to handle requests to that endpoint.
- The URL to our endpoint.
Launching our Application
The final step in our API-building journey is launching our API! This is done as follows:
Before calling our app’s run method, we should check that the name of module where we are trying to launch the app from matches the name we’ve declared the app with. If there is a mismatch, the app will not launch.
Note that the Flask documentation advises against launching apps in production environments via the run method. Flask’s built-in server is not designed to meet the performance or security needs of production servers. You should only use run for testing purposes.
The Flask website lists some options for production deployment — make sure to check them out.
If you’ve done everything correctly, you should see a message like this:
Note the IP address at the last line — it indicates the address of the machine the app is running on. In our case, the application is running on a local machine. http://127.0.0.1:5000 is the default localhost address on pretty much any appliance — unless you’ve changed anything in your setup, your localhost address should be the same.
Performing Predictions Through Our App
Now that we’ve got our application set up, sending requests to it is really easy. If you’ve read our inference guide for Hugging Face, the code will be familiar to you:
Essentially, we’ve made a really simple replica of the Hugging Face Inference API! Behind the scenes, the Inference API has got much more going on, but still, this is how you get started with building your own API!
The variable url contains the hyperlink to our endpoint. If you are running the app on a local machine, you should use its localhost address (http://127.0.0.1:5000). If the app is running on another machine on your network, you should plug its IP address instead.
To perform a query, we need to call query, passing our URL and sequence. The result of a query with a single sample would be as follows:
{'Predictions': ['sadness']}As for batch queries, they would be performed like this with our implementation:
And the output would be as follows:
{'Predictions': ['sadness', 'joy']}Using Our Hugging Face Model in a Real Web Application
You can use the API code from above to build your own application that would do predictions based on user input. We encourage you to try and build a usable app yourself, but to give you a head start, we’ve created a front-end using React; an industry-leading JavaScript library for building user interfaces.
We aren’t going to dive into the code of the app in this post — if you’re interested, have a look at its GitHub repository and try to run the app on your local machine! Below, we’ll provide instructions on setting up and running the app locally.
Cloning the Project
First up, you should clone the project to your machine. This is very easy to do with Git. If you don’t have Git, click here to view available versions for your platform along with installation instructions.
Once you’ve set up Git, run:
git clone https://github.com/sean-mcclure/Hugging_Face_Tutorial.git
…in the terminal.
Setting up the API URL
Navigate to app/hugging_face_app/src/ on your machine and open config.js in an editor. You’ll see something like this:
Here, plug in the URL, port, and the endpoint name specified in your API code. Don’t put backslashes in api_endpoint or “http://” or “https://” in api_url.
Another thing you may need to do is edit the fetch request in app/hugging_face_app/src/events.js. By default, it will look like this:
Leave this unedited for your first run. If you aren’t able to obtain predictions, restructure the fetch request like so:
Installing Dependencies and Starting Web Servers
Although the app will install dependencies upon launch, you will need to have Node.js and Yarn on your machine to be able to run it.
You can install Yarn using the npm package manager of Node.js. Install Node.js on your machine and then run the following command in the terminal:
npm install --global yarnThen, navigate to the cloned repository on your machine and run the following command in the terminal:
bash start.shThis will run a shell script that sets up dependencies and launches the app.
Note that ports 3000 and 5000 should be publicly available on your machine. These are the ports used by the web app and the API.
It may take some time for the web servers and API to fully launch. The servers and API will be ready once you see the following message in terminal:

While the web servers are launching, you may see the web app being opened in your web browser.
Using the web app to make predictions
If you’ve done everything right, the web app should be visible in your web browser. If not, go to http://localhost:3000/. By default, the app should run on port 3000 — if that’s not the case for you, change the port number in the URL.
The web app will look like this:
The grey box on the left takes input sequences, while the dark blue box on the right will show the relative percentages of tweet moods. Note that the app use line breaks (“\n”) to split tweets.
You may type in sequences on your own, but for convenience, you may use All My Tweets to obtain a batch of tweets from any Twitter user. Click the red button near the top of the page to visit All My Tweets.
You will need to log in to your Twitter account to use the service. If you don’t have a Twitter account, just plug in sequences of your own to see how the app works.
Once you’re logged in to your Twitter account:
- Type the username of some Twitter user.
- Choose Tweets.
You’ll see something like this:

Copy the tweets and paste them into the gray input box in the web app. Remove the dates at the end of the pasted sequences since they may affect predictions.
Once you’ve cleaned the tweets, click the arrow between the boxes to obtain the distribution of tweet moods:
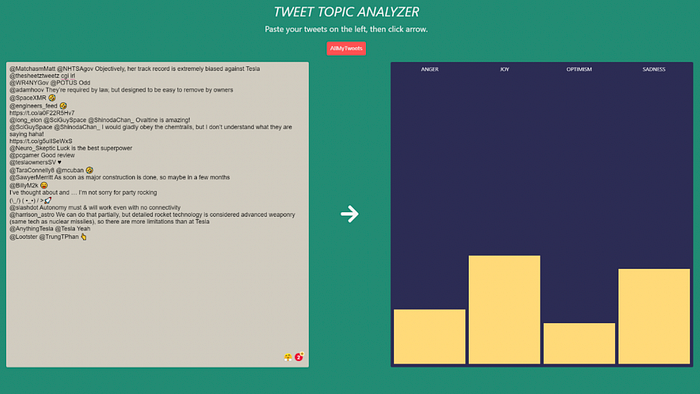
And that’s it for our web app’s functionality! Note that the UI doesn’t allow you to extract predictions or percentages of tweet moods, but maybe that’s something that you should try doing yourself!
Next Steps
Next, try to understand the code behind the app and maybe extend it or build something new with it. You’ll find the code underlying the app in app/hugging_face_app/src.
To get started, you could try editing the source code of the app to make a more sophisticated UI or add functionality. Then, you could try building a React app from scratch — this may be necessary if you want functionality way different from what we have in our app.
