AutoML Framework Comparison

Written by Tigran Avetisyan
This is Part 3 of our 3 PART SERIES on the AutoML capabilities of H2O and TPOT.
See PART 1 here and PART 2 here.
In Part 1, we’ve explored the ecosystem of the H2O machine learning and data analytics framework and tested its AutoML features. In Part 2, we’ve had a look at the TPOT AutoML framework and compared it with H2O AutoML in terms of performance, ease of use, and more.
In this post, we are going to build a Python API on top of TPOT and use it in a React web app. Although TPOT is very intuitive — especially if you know scikit-learn — wrapping it in a user interface can make running repeated experiments much easier. A front end could also be useful if you, for example, wanted to build a beginner-friendly AutoML product (not necessarily with TPOT).
Read on to find out more about the app’s design and the technical details of its implementation!
The Inspiration for the TPOT React App
H2O’s Flow web interface served as the inspiration for our TPOT web app. More specifically, the TPOT app was based on the section in Flow that allows users to quickly pick parameters and run the H2O AutoML algorithm.
The AutoML interface in Flow can be found under Model -> Run AutoML… and looks like this:

The goal of this project was to mimic this interface with TPOT while keeping in mind the framework’s unique features. With that, at a high level, the TPOT app will allow users to:
- Select a dataset for training.
- Select values for TPOT optimizer parameters.
- Download the pipeline script generated by the optimizer’s
exportmethod.
Prerequisites for the App
There are two aspects for you to keep in mind when it comes to prerequisites and dependencies:
- Python packages.
- The web application environment.
To handle the Python side of things, run these two commands in the terminal first:
pip install numpy scipy scikit-learn pandas joblib torchand…
pip install deap update_checker tqdm stopit xgboostIf you are using Anaconda, use conda install instead of pip install.
After you’ve installed these packages, install TPOT by running pip install tpot or conda install -c conda-forge tpot (Anaconda).
In addition, install Flask, Flask-CORS, and Flask-RESTful. These are the packages we will be using to build the Python API for the app.
pip install flask flask_cors flask_restfulInstead of Flask, you may use any other API framework, like FastAPI.
For web development, you will need to install Node.js on your machine. Visit the website of Node.js and follow the installation instructions to set up Node in your environment.
If you aren’t going to be building an API yourself and just want to run the app, you will only need Node.js. Python dependencies will be handled by the app.
Building the API
As a first step, we need to build a Python API to handle HTTP requests from the web app. If you’ve read our post about building an API for Hugging Face, the steps below will be familiar to you.
Importing dependencies
We will need quite a few packages to build the API. Run this code to import dependencies:
Setting up the API
Next, we need to set up a Flask application:
Like in our Hugging Face post, we use:
- The class
Flaskto create a WSGI (web server gateway interface) application. - The class
CORSto handle Cross-Origin Resource Sharing (CORS) for the app. - The class
Apito create an entry point for our Flask application.
After this, we need to set up the arguments that are expected to be passed to the API through HTTP requests:
Here, we specify RequestParser objects to store our arguments. We use separate RequestParser objects for our data (data_parser) and TPOT parameters (args_parser) to simplify the handling of provided values.
For each of the arguments, we specify its name, the datatype it should be converted to by the API, and a help string that will be displayed whenever invalid values are provided. For data and mode, we’ve also set required to True to indicate that they are required arguments.
Two things to notice here:
- For a number of integer parameters (like
generations,offspring_size, andmax_time_mins), the datatype is set tostrrather thanint. This is done because TPOT allows these values to beNoneand because we need a way to handle cases when the string value “None” is passed as a value for these parameters from the web app. - The argument
log_filehas a default value ofapp/TPOT_web_app/logs.txt. Wheneververbosityis not 0, this is the directory on the web server where training logs will be saved. In our implementation of the app, the user cannot choose a custom directory for logs, which is why we define a default value here.
Building an Endpoint for Training
Our next step is to build an endpoint for training. This is the endpoint that our training requests will be directed to.
As a reminder, to create an endpoint with Flask-RESTful, we need to:
- Subclass the Flask-RESTful class
Resource. - Implement our HTTP methods inside the endpoint class.
Here’s how you may go about this task with TPOT:
In this perhaps intimidating piece of code, we perform the following steps:
- Retrieve our data and TPOT config args (lines 6 and 7).
- Define the names of the arguments that can accept
Noneas input (line 10 to line 17). - Define the names of the numeric arguments that can accept
Noneas input (line 20 to line 25). - Handle the values passed for the arguments defined in steps 2 and 3 (line 28 to line 34). For numeric arguments, we convert the provided values to integers if they are not the string “None” (lines 30 and 31). Otherwise, for all cases when the values are “None”, we convert them to Python’s
None(lines 33 and 34). - Initialize the proper TPOT optimizer object based on the value provided to the argument mode (line 37 to line 40).
- Preprocess the JSON dataset and convert it from a JSON string to a pandas
DataFrame(line 43). To do this, we use thepd.io.json.read_jsonfunction. - Break our
DataFramedown intofeaturesandlabels(lines 45 and 46). - Fit the pipeline optimizer with the features and labels (line 49).
- Export the script of the best pipeline (line 52).
- If everything went OK, return a success message and the status code 200 (line 55).
Next, we add the endpoint to our app like so:
Here, we pass our endpoint class and the endpoint URL to the add_resource method of api.
Note that in contrast to our Hugging Face app where we used GET, we are using the HTTP POST method to handle calls. A few reasons for this:
POSTrequests are not cached and don’t remain in browser history.POSTrequests don’t have length limits.- The payload in
POSTrequests, unlikeGETrequests, isn’t encoded as part of the URL. This makes the URL neater and makes sure that the payload is hidden from eavesdroppers.
All in all, POST requests are neater and more convenient to use with large data, like machine learning datasets. The POST method is also more secure since it doesn’t expose the payload like GET does.
Launching the API
We can finally launch our application and serve requests! Here’s how to run our Flask app:
Using our API in a React Application
The API we’ve just built isn’t even remotely useful to end users. We can, of course, send requests programmatically, but how is this helpful to people who don’t have the knowledge or the time to do so?
Here’s where we could go one step further and encase our API in a web application!
To build the front end for our TPOT API, we’ve used the React framework for JavaScript. You can find the source code for the app in this GitHub repo. Feel free to use the app as a launch platform for your future projects!
Cloning the Project
To get started, you need to clone the GitHub repo of the app to your local machine. The most convenient way to do this is to use git — you can find installation instructions for git here.
The git version for Windows also includes Git Bash — an app that emulates the Bash shell used in Unix-like systems and macOS. We will be using Git Bash on Windows to run the app.
To clone the app’s repo to your machine, run the following command in the terminal:
git clone https://github.com/tavetisyan95/TPOT_web_app.gitStarting in Docker
To make things even easier, and to ensure all the project’s dependencies are nicely packaged, we recommend you use Docker to run the application. After cloning the codecase as above, change into its root directory and run the following (if you don’t already have Docker installed on your local machine, see here).
docker-compose -f docker-compose.yaml up -d --build
This will intstall everything needed, start the Flask API service, and start the web service for the front-end. We recommend you use the Docker Dashboard to launch the application:
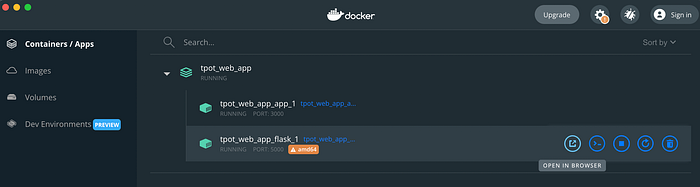
Simply click on the OPEN IN BROWSER icon and the application should open and be ready to run.
Using the App
The app looks like this:
The app allows us to tweak TPOT’s parameters, but it has some limitations:
- Not all parameters of TPOT have been included in the app. More specifically, we didn’t implement
memory(because this parameter has complex behavior),periodic_checkpoint_folder(because the app doesn’t allow users to download individual pipelines), anddisable_update_check(because the app doesn’t allow users to update TPOT on the web server anyway). - Users cannot set up a custom directory for training logs. The log directory is defined in the API Python code, as we saw earlier.
- Some parameters — like
config_dict,scoring, andcv— accept more complex inputs than just strings or integers. For example, TPOT’sconfig_dictcan take custom configuration dictionaries, whilescoringaccepts custom scoring functions. These complex behaviors were not taken into account in the app. - TPOT defines that the sum of
mutation_rateandcrossover_ratemust not exceed 1.0. The app doesn’t handle invalid inputs for these parameters in any way — you can pass any value between 0.0 and 1.0 for either of them. You’ll still get errors in the terminal, but the app doesn’t give any on-page warnings that invalid inputs have been selected.
The webpage lists accepted datatypes and value ranges for each parameter for your convenience. We’ve set some light default values for the parameters to allow you to quickly train models.
Running TPOT AutoML
To start training, you need to do three things:
- Select a CSV dataset for training. Two test datasets can be found in the app’s directory — “dataset_classification.csv” for classification and “dataset_regression.csv” for regression.
- Select the training mode — classification or regression. Note that you will need to manually pass an appropriate value for
scoringfor each of the modes. By default,scoringis set to “accuracy”, and the app doesn’t automatically set metrics based on mode. - Select values for the provided parameters.
Note that your CSV dataset should not contain an index column. The app doesn’t handle index columns in data — if your dataset contains an index column, it will be included in the DataFrame object, which we do not want to happen.
To obtain a dataset in the required form, you could use a function like this:
Note that the dataset should be cleaned beforehand. The API is only as functional as TPOT when it comes to data preprocessing, so your data should be polished before training.
Once you have a dataset, choose a CSV file from your machine by clicking on Choose File under Training data.

Next, tweak the parameters for training. Remember to plug the name of a proper scoring function in scoring. Consult TPOT’s API reference to learn more about some of the built-in scoring functions.
Once you are done, scroll to the bottom of the page and click on Train. Here’s what will happen next:
- The app will convert the data along with the provided parameters to JSON and will send the JSON object to our Flask server via
POST. - The Flask server will handle “None” values, if any, and will instantiate a TPOT optimizer with the provided parameters.
- The Flask server will read the JSON dataset and convert it to a pandas
DataFrame. - The Flask server will pass the dataset to our TPOT optimizer for training.
- If verbosity isn’t set to 0, the app will display training progress on the webpage, if the optimizer produces any logs. The app extracts the logs from the
logs.txtfile located inapp/TPOT_web_app. This is the file that the TPOT optimizer is set to write its training progress to. - After training is done, the app will show a download link for the Python script generated by TPOT. Named
script.py, the script is located inapp/TPOT_web_app. Click on the link in the app to download the script.
The steps above are defined in app/TPOT_web_app/src/events.js and api/api.py.

then you will see:

One thing to note — if you refresh the webpage after training a TPOT optimizer, the app will show existing training logs and the download link to the script generated in the last training run. The logs and the pipeline script are overwritten each time TPOT is run.
Besides, keep in mind that upon shutdown, the app is designed to empty training logs and delete the pipeline script. You can change this behavior in the app’s shell script.
Our TPOT Web App vs H2O Flow
To point out possible avenues for improvement in our app, we can compare it with H2O Flow. Flow is way out of our little app’s league in terms of features, scalability, and ecosystem, but comparing the two can still be very useful.
Here are a few areas where H2O Flow’s AutoML interface is better:
- Flow is running in an H2O cluster, meaning that it can access variables (such as datasets or models) within its environment.
- Flow isn’t just about AutoML — it gathers all the aspects of H2O in one place. You can view imported data, train different types of H2O models, and make predictions, among other things.
- Flow allows users to import data in a variety of ways. You can use remote SQL databases, local files, or data initialized on the H2O cluster. Not only that, but Flow supports a wide range of separators, can handle datasets with and without headers, and works with formats like CSV, XLS, and ORC.
- Flow is structured like a notebook where you may add or remove cells, execute custom expressions, or save workflows.
These are only some of the areas where our web app and Flow differ. Flow is way more flexible since it is built on top of the H2O ecosystem and has many more features.
Our TPOT app doesn’t really have any advantages over Flow. It is perhaps easier to figure out due to its simplicity, but you can’t use it to build entire ML routines. In theory, you could try to build a Flow-like app around scikit-learn, but this would be a far larger project.
Functionality aside, our app has many technical limitations, including these:
- It doesn’t handle page refreshes well. More precisely, if you refresh the webpage while training, the app will not keep updating training logs, and it will not show a proper download link for the script once training is done. However, refreshing the page after training is complete will show logs and the download link as intended.
- The app doesn’t provide an easy way to interrupt training. The only way to stop training is to shut down the web server.
Next Steps
Our AutoML web app is pretty neat and functional, but there are many areas where it has limitations (some of which we mentioned earlier). Maybe you could address them on your own!
Some of the things you could try to do:
- Implement informative error messages on the webpage if something goes wrong, e.g. if an invalid value is provided or if the sum of
mutation_rateandcrossover_rateis more than 1.0. - Include the remaining parameters for TPOT —
memory,periodic_checkpoint_folder, anddisable_update_check. - Allow the user to set up a custom directory for training logs.
- Allow the user to pass complex inputs to parameters like
config_dict,memory,scoring, andcv.
