AutoML Framework Comparison

Written by Tigran Avetisyan
This is Part 1 of our 3 PART SERIES on AutoML.
AutoML, or automated machine learning, is a hyper-hot topic right now. On one hand, by automating the most repetitive steps of model building, AutoML allows us to achieve more in less time. On the other hand, automation of machine learning raises concerns about job security since it performs some of the functions of ML engineers.
No matter what you think about AutoML, it’s an undoubtedly interesting and exciting concept that everybody in the ML field should be aware of. Automated machine learning probably shouldn’t be viewed as a threat to job security — rather, we should view it as yet another technology trend that we should be ready to adapt to.
Just like modern ML/DL libraries like TensorFlow or PyTorch allow us not to worry about low-level implementation details and jump straight to building models, AutoML could help us eliminate repetitive steps from our workflows, giving us more time to work on other aspects of our predictive systems.
Many AutoML packages exist today, and though they can be rough around the edges, they can already help us save a significant amount of time by identifying the best model for the task with just a few lines of code. In our AutoML framework comparison series, we are going to introduce you to these two prominent frameworks:
- H2O
- TPOT
Today, our focus is on H2O, while the next post in this series will cover TPOT. Throughout the series, we will talk about these frameworks’ use cases, go over their features, and show them in action with code!
But now, let’s have a look at H2O!
What Is H2O?
The team behind H2O describes the framework as a machine learning and predictive analytics platform focused on performance and scalability. H2O is intended to facilitate the building and deployment of ML models in enterprise environments.
When it comes to the framework’s technical implementation, here’s what the H2O team writes.
H2O’s core code is written in Java. Inside H2O, a Distributed Key/Value store is used to access and reference data, models, objects, etc., across all nodes and machines. The algorithms are implemented on top of H2O’s distributed Map/Reduce framework and utilize the Java Fork/Join framework for multi-threading. The data is read in parallel and is distributed across the cluster and stored in memory in a columnar format in a compressed way. H2O’s data parser has built-in intelligence to guess the schema of the incoming dataset and supports data ingest from multiple sources in various formats.
So, although H2O has packages in Python and R, it is written in Java under the hood. H2O also allows you to leverage Apache Hadoop and Spark for distributed computing and large-scale data processing, and it is compatible with containerization via Docker and Kubernetes.
H2O operates a bit differently from more traditional ML packages like scikit-learn, TF, or PyTorch. H2O is run on clusters (servers) that can be deployed locally or remotely. The package’s built-in REST API provides access to remote H2O instances via JSON over HTTP. You can perform operations on an H2O cluster programmatically, or you can leverage the Flow user interface to minimize code usage.
Algorithms implemented in H2O
H2O implements a number of machine learning algorithms. More specifically, it has the following supervised algorithms:
- Automatic Machine Learning
- Cox Proportional Hazards (CoxPH)
- Neural Networks
- Distributed Random Forest (DRF)
- Generalized Linear Model (GLM)
- Maximum R Square Improvements (MAXR)
- Generalized Additive Models (GAM)
- ANOVA GLM
- Gradient Boosting Machine (GBM)
- Naive Bayes Classifier
- RuleFit
- Stacked Ensembles
- Support Vector Machine (SVM)
- XGBoost
H2O also has unsupervised algorithms:
- Aggregator
- Generalized Low Rank Models (GLRM)
- Isolation Forest
- Extended Isolation Forest
- K-Means Clustering
- Principal Component Analysis (PCA)
Of all these, the AutoML algorithm is obviously of most interest to us today.
Implementation of AutoML in H2O
Automated machine learning in H2O is based on automated hyperparameter optimization. This means that the H2O AutoML algorithm repeatedly trains candidate models with different hyperparameters to identify the best algorithm.
As of version 3.34.0.3, H2O had the following algorithms in its AutoML toolbox:
- DRF (including Distributed Random Forest, or DRF, and Extremely Randomized Trees, or XRT)
- GLM (Generalized Linear Model with regularization)
- XGBoost (not available on Windows machines)
- GBM (Gradient Boosting Machine)
- DeepLearning
- StackedEnsemble (includes an ensemble of the base models and ensembles using different subsets of the base models)
The hyperparameter spaces for each of these models are listed in the H2O documentation.
GLM hyperparameters:
XGBoost hyperparameters:
GBM hyperparameters:
Deep learning hyperparameters:
As of H2O 3.34.0.3, these hyperparameters were defined in the classes of their respective algorithms and couldn’t be changed easily, and there were no instructions in the documentation on how they can be tweaked. You could, in theory, try to subclass these classes and plug in your own hyperparameter values, but this may not be easy because the core of H2O is written in Java.
Data manipulation with H2O
H2O implements its own class for data storage called H2OFrame. H2OFrame is similar to R’s data.frame and pandas’s DataFrame.
With H2OFrame, data generally is not held in memory — rather, it is located on an H2O cluster, which may be remote. H2OFrame serves as a handle to the data assigned to it.
H2OFrame allows users to perform data manipulation, including:
- Locating and filling missing values.
- Converting data to numeric, string, or date formats.
- Scaling the data.
- Merging or splitting datasets.
- Tokenizing strings into tokens.
- Computing statistical measures such as kurtosis, standard deviation, or the mean.
All in all, if you’ve ever used pandas, you will see that H2OFrame is similar to its DataFrame class. Among other things, H2OFrame and DataFrame use the same names for many of their functions, so transitioning to H2OFrame should be fairly easy for pandas users.
H2O also allows users to perform target encoding and convert text to word vectors.
Prerequisites For Using H2O In Python Environments
H2O is not like other machine learning/deep learning packages in Python when it comes to installation. Since it’s implemented in Java, you need not only the H2O Python package but also a Java environment set up on your machine.
Regarding Java, you have two options:
- If you intend to build H2O and run H2O tests, you will need a 64-bit Java Development Kit. H2O supports Java JDK versions 15, 14, 13, 12, 11, 10, 9, and 8, though it may work on newer versions as well. Click here to view the latest supported versions.
- If you only intend to run H2O in command line, Python, or R, you only need 64-bit Java installed on your machine.
If you are going to leverage Hadoop or Spark, you will need to have them installed as well.
Once you’ve got Java set up, install the prerequisites for the H2O package for Python using the pip package manager, like so:
pip install requests
pip install tabulate
pip install futureYou may have these already, but if you’re not sure, run the commands just in case.
Next, install the H2O package itself:
pip install h2oNote that we were having issues running the AutoML algorithms on H2O version 3.34.0.1. More specifically, whenever the AutoML algorithm was run, the package would throw H2OServerError: HTTP 500. If you encounter a similar issue for no apparent reason, try downgrading to an older version of H2O by first uninstalling H2O and then installing the desired version:
pip uninstall h2o
pip install h2o==3.32.1.73.32.1.7 was the version used for this project, but you may try other releases if things don’t work for you.
Using Automated Machine Learning With H2O
Now that we understand what H2O is — in a general sense — let’s try building an AutoML algorithm with it!
Note that we will be covering only the basics of AutoML with H2O in this post — the package’s capabilities are quite wide, so you will need to explore many of the things on your own.
Setting Up The H2O Environment
First things first, we need to import necessary packages/modules and set up an H2O environment.
Here’s what we will be importing right now:
Next, we need to launch a local H2O cluster. This is done with the help of the h2o.init method:
We specified a name for our cluster (via parameter name) as well as the number of allowed threads (nthreads). If you are just trying out H2O, you should set nthreads lower than your CPU’s number of threads. This is so that you don’t fully load the CPU while training and can continue using your machine without performance hiccups.
In production environments, you would obviously want to use as many threads as possible.
By default, H2O will try to start a cluster at localhost:54321. If you don’t want this, you can specify your own URL or IP address for the cluster.
h2o.init has many parameters, but you don’t need to use any of them if you want basic functionality. If necessary, you could specify things like:
- Usernames and passwords.
- Proxy server addresses.
- Cookies to be added to each request.
- Maximum memory provided to the H2O cluster.
- The number of threads available to the cluster.
Once you launch the cluster, you are going to see something like this:
If you navigate to http://127.0.0.1:54323/ in your web browser once your H2O server is running, you will be able to access H2O Flow — a user interface for your H2O server. There, you can inspect your data, models, make plots, or train models with minimal code.

Preparing Data For Training
Loading data
Once we have our cluster set up, we can start preparing our dataset for training!
To keep things simple and be able to start training without too many preprocessing steps, we are going to be using sklearn’s breast cancer dataset.
This particular dataset is pretty much ready for training out of the box. With other datasets, you may need to preprocess your data. Note that as of this guide’s writing, H2O could only do preprocessing via target encoding.
Back to our code — data is a dictionary containing features and labels, among some other things. The keys of data are as follows:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])Splitting data into train and test sets
Let’s split our data into train and test sets using sklearn’s train_test_split function. The train set will be used for training and k-fold cross-validation, while the test set will be used to demonstrate inference with the trained model.
Converting data into H2OFrame objects
Next, we need to feed our data into H2OFrame objects since that’s the expected input format for H2O models.
There are three ways to create H2Oframe objects from existing data:
- Passing a Python object (such as pandas DataFrames, NumPy arrays, Python lists or tuples, or dictionaries) to the H2OFrame class.
- Using h2o.upload_file to upload a dataset from a local path to a remote H2O cluster.
- Using h2o.import_file to create an H2OFrame from data already located on a remote H2O cluster.
When executing on local machines, h2o.upload_file and h2o.import_file do the same thing.
We will be using the first method to create H2OFrame objects. Here’s how:
Here, note that aside from our data, we are also supplying column names. We don’t need to do this, but this will make our frames more understandable.
Feature column names are contained under the “feature_names” key of our sklearn dataset. The name “target” for the label column is arbitrary.
Next, we join our features and labels to create train and test frames via the H2OFrame.cbind method:
The contents of our training frame are as follows:
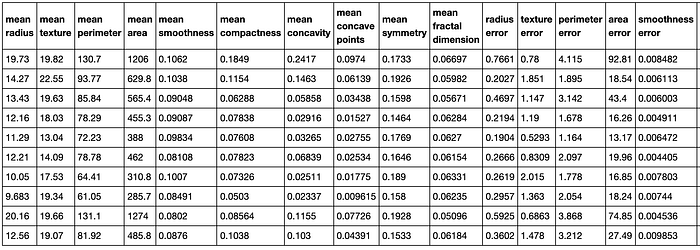
Identifying features and labels
Next, we need to specify the predictor (feature) and response (label) column names in our dataset. This is necessary so that our AutoML object knows which data to use for training and which data to use to measure training performance.
Here, we:
- Obtain the column names in our dataset. We can use the column names of the train set since they are also present in the test set.
- Specify the name of the label column (“target” in our case).
- Remove the label column name (y) from our column names (x).
In the end, we get a variable x containing our predictors and a variable y with the name of our response column.
Note that if you want to use all features in your dataset for training (like in our case), you do not need to specify an x list/vector with their names. This is only necessary when you want to exclude not only the target but also some of the predictors from the data.
In our case, creating x is redundant, but it’s useful for demonstration purposes so that you know how to exclude feature columns from training.
Converting integer labels to categoricals
Next, we need to convert our integer labels to categoricals via the H2OFrame.asfactor method. In more technical terms, this method converts columns into the enum datatype. This is necessary so that our AutoML algorithm treats the data as a classification dataset. If we don’t do this step, the algorithm will treat the task as regression.
Training Our AutoML Algorithm
Setting the algorithm up
Now that our data is ready, we can proceed to the training!
The first step to do here is to create an H2OAutoML object:
The H2OAutoML has many optional parameters that can be set by the user. However, there are two important parameters you should know about.
- max_models: the number of models to try in one run. This number excludes Stacked Ensemble models.
- max_runtime_secs: the number of seconds the AutoML algorithm will be allowed to run. This parameter defaults to 0, i.e. no limit.
If both of these options are set, training will stop once one of the limits is hit. If none are set, the training time limit is automatically set to 1 hour.
Note that in H2O versions older than 3.34.0.1, training may stop before max_runtime_secs expire. This is because early stopping is enabled in previous versions by default.
For this project, let’s set the max runtime to 600 seconds, or 10 minutes. This may undercut training performance — try setting longer times and see how this affects your training results!
Other notable parameters of H2OAutoML are:
- nfolds: specifies the number of folds for cross-validation. The default value is 5.
stopping_metric: the metric used for early stopping. If not specified, defaults tologlossfor classification anddeviancefor regression.sort_metric: the metric by which models will be sorted in the leaderboard after training. By default, models are sorted byAUC(area under the curve) for binary classification,mean_per_class_errorfor multinomial classification, anddeviancefor regression.seed: an integer seed for reproducibility. If H2O deep learning models are used in training, AutoML results won’t be fully reproducible since H2O deep learning models are not deterministic for performance reasons.exclude_algos: a list of the string names of algorithms that should NOT be used in training.include_algos: a list of the string names of algorithms that should be used in training. Defaults toNone, meaning that all appropriate models will be used.
Training the AutoML algorithm
To commence training, just call the AutoML object’s train method, passing the required parameters:
You must specify values for two parameters to start training:
- y: the name or index of the response (label) column.
- training_frame: the H2OFrame object with the training data.
In our code, we’ve also passed x — our list with the names or indexes of predictor columns — for demonstration purposes. You don’t need to do this if you want to use all predictor columns, as mentioned earlier.
If necessary, you could also pass a validation frame to the validation_frame parameter, but that doesn’t make much sense when k-fold cross-validation is enabled.
Obtaining the best model
Once training is complete, we can view the results achieved by the selected algorithms by accessing the leaderboard attribute of aml:
AutoML progress: | 14:53:30.993: AutoML: XGBoost is not available; skipping it. ████████████████████████████████████████████████████████| 100%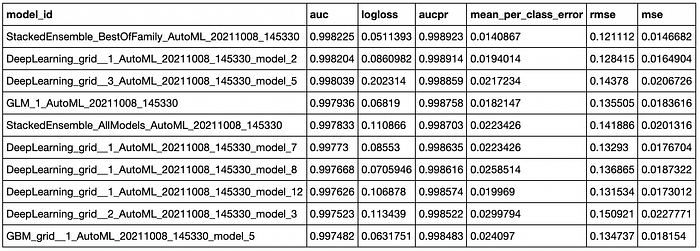
Here, models are sorted by AUC since this is a classification problem.
We can then obtain the best model by calling the AutoML object’s leader attribute:
If you are interested in a specific metric or a specific model type, you can obtain the best model by using the AutoML object’s get_best_model method.
To obtain the best model based on a metric, pass the name of the desired metric to the parameter criterion of get_best_model. To obtain the best model of a specific type, pass the name of the model to the parameter algorithm. You may pass both a metric and model type if you want to get the best model of a specific type based on a specific metric.
Inspecting the best model
If we inspect the contents of best_model, we are going to see a whole bunch of interesting stuff.
If you inspect your model object, you may see things like these:
Model type:
Model Details ============= H2OStackedEnsembleEstimator : Stacked Ensemble Model Key: StackedEnsemble_BestOfFamily_AutoML_20211008_145330 No model summary for this modelModel training metrics:
ModelMetricsBinomialGLM: stackedensemble ** Reported on train data. ** MSE: 0.00024973344538977067 RMSE: 0.015802956855910565 LogLoss: 0.0023149158320803468 Null degrees of freedom: 454 Residual degrees of freedom: 452 Null deviance: 601.3803498951446 Residual deviance: 2.106573407193115 AIC: 8.106573407193114 AUC: 1.0 AUCPR: 1.0 Gini: 1.0
Model cross-validation metrics:
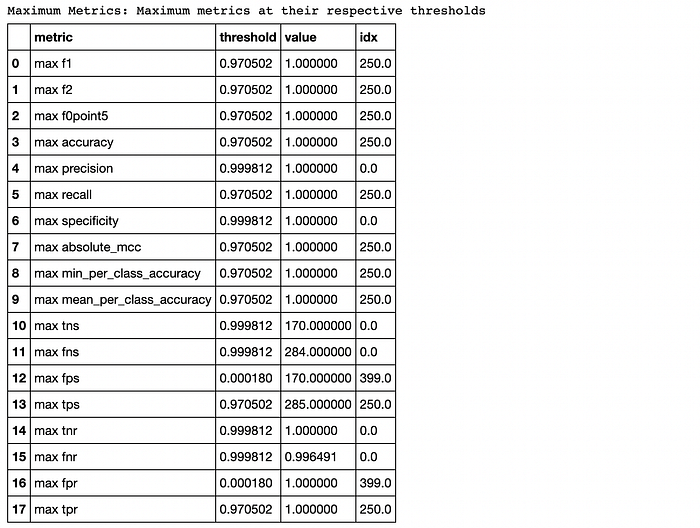
Note that different models may give different tables. For example, deep learning models contain tables for feature importances and model architecture.
Inference with the best model
To perform predictions with the selected model, we need to call its predict method and pass data to it, like so:
The output is as follows:

We can see the first ten predictions here. The column predict contains the prediction, while columns p0 and p1 contain the probabilities of class 0 and class 1 respectively.
Saving and loading the best model
If you want to save the leader model, run the following code:
Here, we:
- Pass our model to the
modelparameter. - Pass the target directory to the
pathparameter. - Allow overwrites of existing directories by setting
forcetoTrue.
You can print model_path to view the full path to the saved model.
If your model is located on a remote H2O cluster, then use h2o.download_model instead, but drop the force parameter since that method doesn’t have it.
To load a locally saved model, we call the h2o.load_model method and pass the model’s directory to it:
If you need to upload a model from a local machine to a remote H2O cluster, you need to first use the h2o.upload_model method and then load the model from the cluster.
Our Impressions of H2O and Suggested Next Steps
That’s it for the basics of AutoML with H2O! H2O can do way more than just automated machine learning, but this guide has covered many of the important things you need to know to get started.
Overall, H2O appears to be an excellent choice for projects that incorporate large amounts of data and require scalability. H2O should work particularly well in Hadoop and Spark environments. And if you also happen to be learning Hadoop and/or Spark, using H2O may allow you to do several things at once.
The explainability interface — which we didn’t cover in this post — deserves praise as well since it provides deeper insight into our data and H2O model architectures.
With all that said, the framework definitely has room for improvement. The biggest downsides we noticed with H2O AutoML are as follows:
- Lack of direct control over the hyperparameters tested by the AutoML algorithm.
- The documentation could be better — descriptions of H2O methods and classes are at times vague and lack usage examples. You may need to figure out some things on your own by diving into source code or via trial and error.
- Little to no automatic data preprocessing — as of H2O 3.34.0.3, only target encoding was supported. So feature selection and preprocessing will be on you.
In PART 2 of our “AutoML Framework Comparison” series, we are going to have a look at TPOT — an AutoML framework with drastically different implementation and capabilities!









